转自极客时间,仅供非商业用途或交流学习使用,如有侵权请联系删除
1. 常用的序列化框架
当进行远程跨进程服务调用时,需要把被传输的数据结构/对象序列化为字节数组或者ByteBuffer。而当远程服务读取到ByteBuffer对象或者字节数组时,需要将其反序列化为原始的数据结构/对象。利用序列化框架可以实现上述转换工作。
1.1 Java默认的序列化机制
Java序列化从JDK 1.1版本就已经提供,它不需要添加额外的类库,只需实现java.io.Serializable并生成序列ID即可,因此,它从诞生之初就得到了广泛的应用。
但是在远程服务调用(RPC)时,很少直接使用Java序列化进行消息的编解码和传输,这又是什么原因呢?下面通过分析Java序列化的缺点来找出答案:
缺点1:无法跨语言,是Java序列化最致命的问题。对于跨进程的服务调用,服务提供者可能会使用C或者其他语言开发,当我们需要和异构语言进程交互时,Java序列化就难以胜任。
由于Java序列化技术是Java语言内部的私有协议,其它语言并不支持,对于用户来说它完全是黑盒。对于Java序列化后的字节数组,别的语言无法进行反序列化,这就严重阻碍了它的应用。
事实上,目前几乎所有流行的Java RPC通信框架,都没有使用Java序列化作为编解码框架,原因就在于它无法跨语言,而这些RPC框架往往需要支持跨语言调用。
缺点2:相比于业界的一些序列化框架,Java默认的序列化效能较低,主要体现在:序列化之后的字节数组体积较大,性能较低。
在同等情况下,编码后的字节数组越大,存储的时候就越占空间,存储的硬件成本就越高,并且在网络传输时更占带宽,导致系统的吞吐量降低。Java序列化后的码流偏大也一直被业界所诟病,导致它的应用范围受到了很大限制。
1.2 Thrift序列化框架
Thrift源于Facebook,在2007年Facebook将Thrift作为一个开源项目提交给Apache基金会。
对于当时的Facebook来说,创造Thrift是为了解决Facebook各系统间大数据量的传输通信以及系统之间语言环境不同需要跨平台的特性,因此Thrift可以支持多种程序语言,如C、Cocoa、Erlang、Haskell、Java、Ocami、Perl、PHP、Python、Ruby和Smalltalk。
在多种不同的语言之间通信,Thrift可以作为高性能的通信中间件使用,它支持数据(对象)序列化和多种类型的RPC服务。
Thrift适用于静态的数据交换,需要先确定好它的数据结构,当数据结构发生变化时,必须重新编辑IDL文件,生成代码和编译,这一点跟其他IDL工具相比可以视为是Thrift的弱项。
Thrift适用于搭建大型数据交换及存储的通用工具,对于大型系统中的内部数据传输,相对于JSON和XML在性能和传输大小上都有明显的优势。
Thrift主要由5部分组成:
- 语言系统以及IDL编译器:负责由用户给定的IDL文件生成相应语言的接口代码;
- TProtocol:RPC的协议层,可以选择多种不同的对象序列化方式,如JSON和Binary;
- TTransport:RPC的传输层,同样可以选择不同的传输层实现,如socket、NIO、MemoryBuffer等;
- TProcessor:作为协议层和用户提供的服务实现之间的纽带,负责调用服务实现的接口;
- TServer:聚合TProtocol、TTransport和TProcessor等对象。
我们重点关注的是编解码框架,与之对应的就是TProtocol。由于Thrift的RPC服务调用和编解码框架绑定在一起,所以,通常我们使用Thrift的时候会采取RPC框架的方式。
但是,它的TProtocol编解码框架还是可以以类库的方式独立使用的。
与Protocol Buffers比较类似的是,Thrift通过IDL描述接口和数据结构定义,它支持8种Java基本类型、Map、Set和List,支持可选和必选定义,功能非常强大。因为可以定义数据结构中字段的顺序,所以它也可以支持协议的前向兼容。
Thrift支持三种比较典型的编解码方式。
- 通用的二进制编解码;
- 压缩二进制编解码;
- 优化的可选字段压缩编解码。
由于支持二进制压缩编解码,Thrift的编解码性能表现也相当优异,远远超过Java序列化和RMI等。
1.3 MessagePack序列化框架
MessagePack是一个高效的二进制序列化框架,它像JSON一样支持不同语言间的数据交换,但是它的性能更快,序列化之后的码流也更小。
MessagePack提供了对多语言的支持,官方支持的语言如下:Java、Python、Ruby、Haskell、C#、OCaml、Lua、Go、C、C等。
MessagePack的Java API非常简单,如果使用MessagePack进行开发,只需要导入MessagePack maven依赖:
<dependency> <groupId>org.msgpack</groupId> <artifactId>msgpack</artifactId> <version>$</version></dependency>它的API使用示例如下:
List<String> src = new ArrayList<String>();src.add("msgpack");src.add("kumofs");src.add("viver");MessagePack msgpack = new MessagePack();byte[] raw = msgpack.write(src);List<String> dst1 =msgpack.read(raw, Templates.tList(Templates.TString));1.4 Protocol Buffers序列化框架
Google的Protocol Buffers在业界非常流行,很多商业项目选择Protocol Buffers作为编解码框架,当前最新的为Protocol Buffers v3版本,它具有如下特点:
- 在谷歌内部长期使用,产品成熟度高;
- 跨语言、支持多种语言,包括C、Java和Python;
- 编码后的消息更小,更加有利于存储和传输;
- 编解码的性能非常高;
- 支持不同协议版本的前向兼容;
- 支持定义可选和必选字段。
Protocol Buffers是一个灵活、高效、结构化的数据序列化框架,相比于XML等传统的序列化工具,它更小、更快、更简单。
Protocol Buffers支持数据结构化一次可以到处使用,甚至跨语言使用,通过代码生成工具可以自动生成不同语言版本的源代码,甚至可以在使用不同版本的数据结构进程间进行数据传递,实现数据结构的前向兼容。
2. Protocol Buffers介绍
区别于Thrift,Protocol Buffers是一个可独立使用的序列化框架,它并不与gRPC框架绑定,任何需要支持多语言的RPC框架都可以选择使用Protocol Buffers作为序列化框架。
Protocol Buffers的使用主要包括:
- IDL文件定义(*.proto), 包含数据结构定义,以及可选的服务接口定义(gRPC);
- 各种语言的代码生成(含数据结构定义、以及序列化和反序列化接口);
- 使用Protocol Buffers的API进行序列化和反序列化。
2.1 支持的数据结构
Protocol Buffers提供了对主流语言的常用数据结构的支持,考虑到跨语言特性,因此对于特定语言的特定数据结构并不提供支持,比较典型的如Java的Exception对象。
2.1.1 标量值类型(基本数据类型)
Protocol Buffers支持的标量值类型如下:
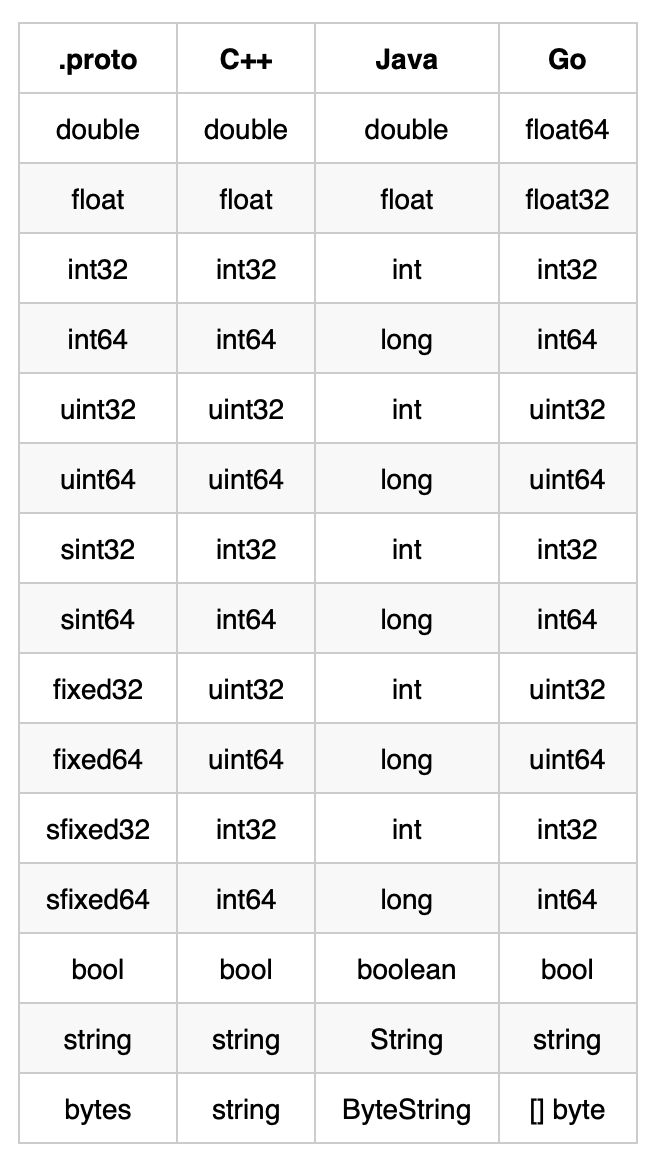
2.1.2 复杂数据类型
通过repeated关键字,标识该字段可以重复任意次数,等价于数组。Protocol Buffers支持枚举类型,定义示例如下:
message QueryInfo{string queryID = 1;enum Types{USER = 0;GROUP=1;OTHERS=2;}Types type = 2;}proto3支持map类型的数据结构,它的定义示例如下:
map<key_type, value_type> map_field = N;message ValueTypemap<string, ValueType> typeMap = 0;对于map数据类型的约束如下:
- 键、值类型可以是内置的基本类型,也可以是自定义message类型;
- 不要依赖键值的迭代顺序;
- 不支持repeated关键字;
- 如果在解析序列化文件的时候出现多个Key的情况,那么将会使用最后一个;如果在解析文本文件的时候出现多个key,那么将会报错。
如果类型不确定,类似Java中的泛型,可以使用proto3中的Any来表示任何类型的数据,它的定义如下:
message PramMap{map<String, google.protobuf.Any> extentionTypes = 1;}通过pack()可以将任何message打包成Any类型,代码如下(Any类):
public static <T extends com.google.protobuf.Message> Any pack( T message) { return Any.newBuilder() .setTypeUrl(getTypeUrl("type.googleapis.com", message.getDescriptorForType())) .setValue(message.toByteString()) .build(); }通过unpack()方法,可以将message从Any类型中取出,代码如下:
public <T extends com.google.protobuf.Message> T unpack( java.lang.Class<T> clazz) throws com.google.protobuf.InvalidProtocolBufferException { if (!is(clazz)) { throw new com.google.protobuf.InvalidProtocolBufferException( "Type of the Any message does not match the given class."); } if (cachedUnpackValue != null) { return (T) cachedUnpackValue; } T defaultInstance = com.google.protobuf.Internal.getDefaultInstance(clazz); T result = (T) defaultInstance.getParserForType() .parseFrom(getValue()); cachedUnpackValue = result; return result; }2.2 IDL文件定义
按照Protocol Buffers的语法在proto文件中定义RPC请求和响应的数据结构,示例如下:
syntax = "proto3";option java_package = "io.grpc.examples.helloworld";package helloworld;message HelloRequest message HelloReply 其中,syntax proto3表示使用v3版本的Protocol Buffers,v3和v2版本语法上有较多的变更,使用的时候需要特别注意。java_package表示生成代码的存放路径(包路径)。通过message关键字来定义数据结构,数据结构的语法为:
数据类型 字段名称 = Tag(field的唯一标识符,在一个message层次中是unique的。嵌套message可以重新开始。用来标识这些fields的二进制编码方式,序列化以及解析的时候会用到)。
message是支持嵌套的,即A message引用B message作为自己的field,它表示的就是对象聚合关系,即A对象聚合(引用)了B对象。
对于一些公共的数据结构,例如公共Header,可以通过单独定义公共数据结构proto文件,然后导入的方式使用,示例如下:
import “/other_protofile.proto”导入也支持级联引用,即a.proto导入了b.proto,b.proto导入了c.proto,则a.proto可以直接使用c.proto中定义的message。
在实际项目开发时,可以使用Protocol Buffers的IDEA/Eclipse插件,对.proto文件的合法性进行校验:

2.3 代码生成
基于.proto文件生成代码有两种方式:
- 单独下载protoc工具,通过命令行生成代码;
- 通过Maven等构建工具,配置protoc命令,在打包/构建时生成代码。
通过protoc工具生成代码流程如下:
第一步,下载Protocol Buffers的Windows版本,网址如下:
http://code.google.com/p/protobuf/downloads/detail?name=protoc-2.5.0-win32.zip&can=2&q=
对下载的protoc-2.5.0-win32.zip进行解压,如下所示:

第二步,编写proto文件,通过执行protoc命令,生成代码:

如果使用maven构建生成代码,则需要在pom.xml中做如下配置:
<plugin> <groupId>org.xolstice.maven.plugins</groupId> <artifactId>protobuf-maven-plugin</artifactId> <version>0.5.0</version> <configuration> <protocArtifact>com.google.protobuf:protoc:3.2.0:exe:$</protocArtifact> <pluginId>grpc-java</pluginId> <pluginArtifact>io.grpc:protoc-gen-grpc-java:$:exe:$</pluginArtifact> </configuration> <executions> <execution> <goals> <goal>compile</goal> <goal>compile-custom</goal> </goals> </execution> </executions> </plugin>2.4 序列化和反序列化接口调用
2.4.1 原生用法
Protocol Buffers使用经典的Build模式来构建对象,代码示例如下:
HelloRequest request= HelloRequest.newBuilder().setName(name).build();完成对象设值之后,可以通过多种方式将对象转换成字节数组或者输出流,代码如下:
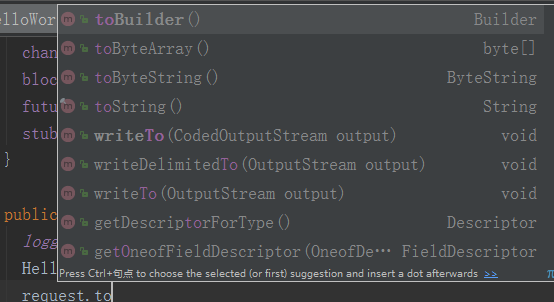
例如,可以通过toByteArray将对象直接序列化为字节数组。
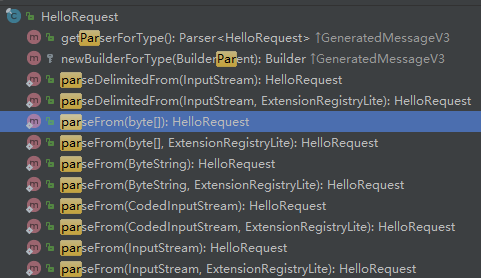
反序列化时,Protocol Buffers提供了多种接口用于将字节数组/输入流转换成原始对象,相关接口如下所示:
2.4.2 Netty中使用
Netty提供了对Protocol Buffers的支持,在服务端和客户端创建时,只需要将Protocol Buffers相关的CodeC Handler加入到ChannelPipeline中即可。
支持Protocol Buffers的Netty服务端创建示例如下:
public void initChannel(SocketChannel ch) { ch.pipeline().addLast( new ProtobufVarint32FrameDecoder()); ch.pipeline().addLast( new ProtobufDecoder( SubscribeReqProto.SubscribeReq .getDefaultInstance())); ch.pipeline().addLast( new ProtobufVarint32LengthFieldPrepender()); ch.pipeline().addLast(new ProtobufEncoder()); ch.pipeline().addLast(new SubReqServerHandler()); }支持Protocol Buffers的Netty客户端创建示例如下:
public void initChannel(SocketChannel ch) throws Exception { ch.pipeline().addLast( new ProtobufVarint32FrameDecoder()); ch.pipeline().addLast( new ProtobufDecoder( SubscribeRespProto.SubscribeResp .getDefaultInstance())); ch.pipeline().addLast( new ProtobufVarint32LengthFieldPrepender()); ch.pipeline().addLast(new ProtobufEncoder()); ch.pipeline().addLast(new SubReqClientHandler()); }3. gRPC序列化原理分析
gRPC默认使用Protocol Buffers作为RPC序列化框架,通过Protocol Buffers对消息进行序列化和反序列化,然后通过Netty的HTTP/2,以Stream的方式进行数据传输。
由于存在一些特殊的处理,gRPC并没有直接使用Netty提供的Protocol Buffers Handler,而是自己集成Protocol Buffers工具类进行序列化和反序列化,下面一起分析它的设计和实现原理。
3.1 客户端请求消息序列化
客户端通过Build模式构造请求消息,然后通过同步/异步方式发起RPC调用,gRPC框架负责客户端请求消息的序列化,以及HTTP/2 Header和Body的构造,然后通过Netty提供的HTTP/2协议栈,将HTTP/2请求消息发送给服务端。
3.1.1. 数据流图
客户端请求消息的发送流程如下所示:
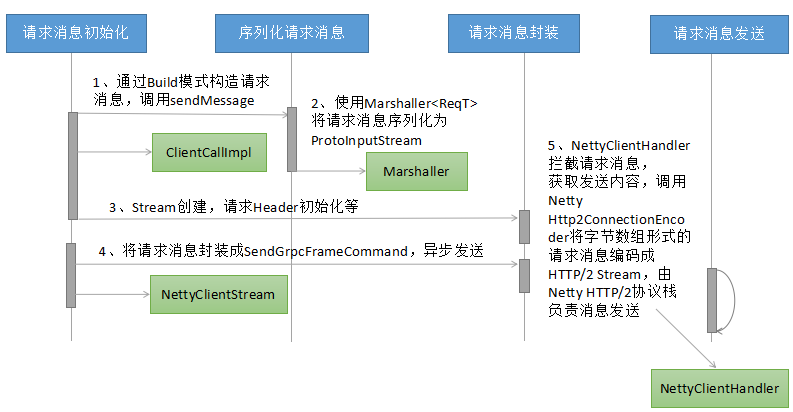
请求消息的序列化主要包含5个步骤:
- 请求消息的构建:使用Protocol Buffers生成的代码,通过build模式对请求消息设值,完成请求消息的初始化;
- 请求消息的序列化:使用Protocol Buffers的Marshaller工具类,对于生成的请求对象(继承自com.google.protobuf.GeneratedMessageV3)进行序列化,生成ProtoInputStream;
- 请求消息的首次封装:主要用于创建NettyClientStream、构造gRPC的HTTP/2消息头等;
- 请求消息的二次封装:将序列化之后的请求消息封装成SendGrpcFrameCommand,通过异步的方式由Netty的NIO线程执行消息的发送;
- gRPC的NettyClientHandler拦截到write的请求消息之后,根据Command类型判断是业务消息发送,调用Netty的Http2ConnectionEncoder,由Netty的HTTP/2协议栈创建HTTP/2 Stream并最终发送给服务端。
3.1.2 工作原理与源码分析
调用ClientCallImpl的sendMessage,发送请求消息(ClientCallImpl类):
public void sendMessage(ReqT message) { Preconditions.checkState(stream != null, "Not started"); Preconditions.checkState(!cancelCalled, "call was cancelled"); Preconditions.checkState(!halfCloseCalled, "call was half-closed"); try { InputStream messageIs = method.streamRequest(message); stream.writeMessage(messageIs);...实际上并未真正发送消息,而是使用Protocol Buffers对消息做序列化(ProtoLiteUtils类):
return new PrototypeMarshaller<T>() { @Override public Class<T> getMessageClass() { return (Class<T>) defaultInstance.getClass(); } @Override public T getMessagePrototype() { return defaultInstance; } @Override public InputStream stream(T value) { return new ProtoInputStream(value, parser); }序列化完成之后,调用ClientStream的writeMessage,对请求消息进行封装(DelayedStream类):
public void writeMessage(final InputStream message) { checkNotNull(message, "message"); if (passThrough) { realStream.writeMessage(message); } else { delayOrExecute(new Runnable() { @Override public void run() { realStream.writeMessage(message); } }); } }根据序列化之后的消息长度,更新HTTP/2 Header的content-length(MessageFramer类):
ByteBuffer header = ByteBuffer.wrap(headerScratch); header.put(UNCOMPRESSED); header.putInt(messageLength);完成发送前的准备工作之后,调用halfClose方法,开始向HTTP/2协议栈发送消息(DelayedStream类):
public void halfClose() { delayOrExecute(new Runnable() { @Override public void run() { realStream.halfClose(); } }); }序列化之后的请求消息通过NettyClientStream的Sink,被包装成SendGrpcFrameCommand,加入到WriteQueue中,异步发送(NettyClientStream类):
public void writeFrame(WritableBuffer frame, boolean endOfStream, boolean flush) { ByteBuf bytebuf = frame == null ? EMPTY_BUFFER : ((NettyWritableBuffer) frame).bytebuf(); final int numBytes = bytebuf.readableBytes(); if (numBytes > 0) { onSendingBytes(numBytes); writeQueue.enqueue( new SendGrpcFrameCommand(transportState(), bytebuf, endOfStream), channel.newPromise().addListener(new ChannelFutureListener() {...通过flush()将发送队列排队的SendGrpcFrameCommand写入到channel中(WriteQueue类):
private void flush() { try { QueuedCommand cmd; int i = 0; boolean flushedOnce = false; while ((cmd = queue.poll()) != null) { channel.write(cmd, cmd.promise()); if (++i == DEQUE_CHUNK_SIZE) { i = 0; channel.flush();...gRPC的NettyClientHandler拦截到发送消息,对消息类型做判断(NettyClientHandler类):
public void write(ChannelHandlerContext ctx, Object msg, ChannelPromise promise) throws Exception { if (msg instanceof CreateStreamCommand) { createStream((CreateStreamCommand) msg, promise); } else if (msg instanceof SendGrpcFrameCommand) { sendGrpcFrame(ctx, (SendGrpcFrameCommand) msg, promise);...调用sendGrpcFrame,通过Netty提供的Http2ConnectionEncoder,完成HTTP/2消息的发送:
private void sendGrpcFrame(ChannelHandlerContext ctx, SendGrpcFrameCommand cmd, ChannelPromise promise) { encoder().writeData(ctx, cmd.streamId(), cmd.content(), 0, cmd.endStream(), promise); }3.1.3 线程模型
请求消息构建、请求消息序列化、请求消息封装都由客户端用户线程执行,示例如下:
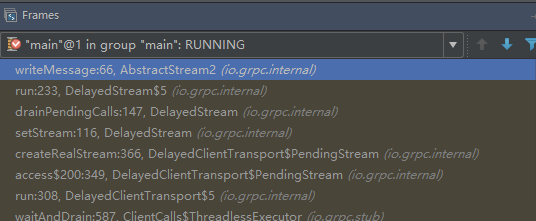
请求消息的发送,由Netty的NIO线程执行,示例如下(Netty的EventLoopGroup):
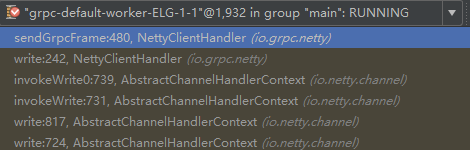
3.2 服务端请求消息反序列化
服务端接收到客户端的HTTP/2请求消息之后,由Netty HTTP/2协议栈的FrameListener.onDataRead方法调用gRPC的NettyServerHandler,对请求消息进行解析和处理。
3.2.1 数据流图
服务端读取客户端请求消息并进行序列化的流程如下所示(HTTP/2 Header的处理步骤省略):
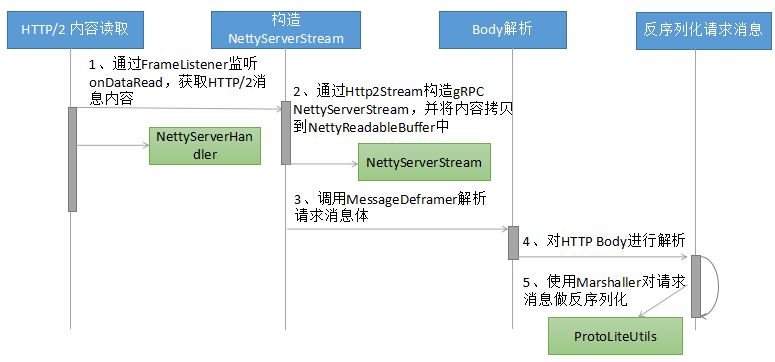
3.2.2 工作原理与源码分析
Netty的HTTP/2监听器回调gRPC的NettyServerHandler,通知gRPC处理HTTP/2消息(NettyServerHandler类):
private void onDataRead(int streamId, ByteBuf data, int padding, boolean endOfStream) throws Http2Exception { flowControlPing().onDataRead(data.readableBytes(), padding); try { NettyServerStream.TransportState stream = serverStream(requireHttp2Stream(streamId)); stream.inboundDataReceived(data, endOfStream);...如果流控校验通过,则调用MessageDeframer处理请求消息(AbstractStream2类):
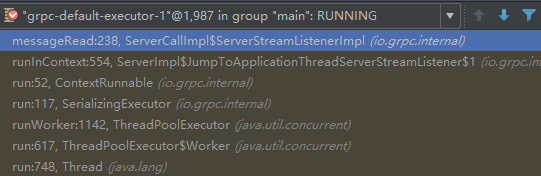
protected final void deframe(ReadableBuffer frame, boolean endOfStream) { if (deframer.isClosed()) { frame.close(); return; } try { deframer.deframe(frame, endOfStream);...异步处理,由gRPC的SerializingExecutor负责body的解析(JumpToApplicationThreadServerStreamListener类):
public void messageRead(final InputStream message) { callExecutor.execute(new ContextRunnable(context) { @Override public void runInContext() { try { getListener().messageRead(message);...调用ProtoLiteUtils的Marshaller,通过parse(InputStream stream)方法将NettyReadableBuffer反序列化为原始的请求消息,代码如下(ProtoLiteUtils类):
public T parse(InputStream stream) { if (stream instanceof ProtoInputStream) { ProtoInputStream protoStream = (ProtoInputStream) stream; if (protoStream.parser() == parser) { try { @SuppressWarnings("unchecked") T message = (T) ((ProtoInputStream) stream).message(); return message;...3.2.3 线程模型
Netty HTTP/2消息的读取和校验等,由Netty NIO线程负责,示例如下:
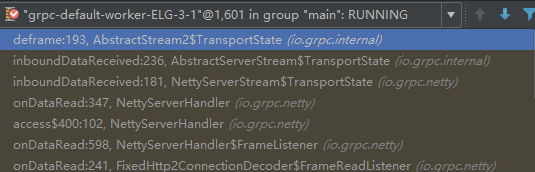
后续HTTP Body的反序列化,则由gRPC的SerializingExecutor线程池完成:
3.3 服务端响应消息序列化
服务端接口调用完成之后,需要将响应消息序列化,然后通过HTTP/2 Stream(与请求相同的Stream ID)发送给客户端。
3.3.1 数据流图
服务端响应的发送流程如下所示:
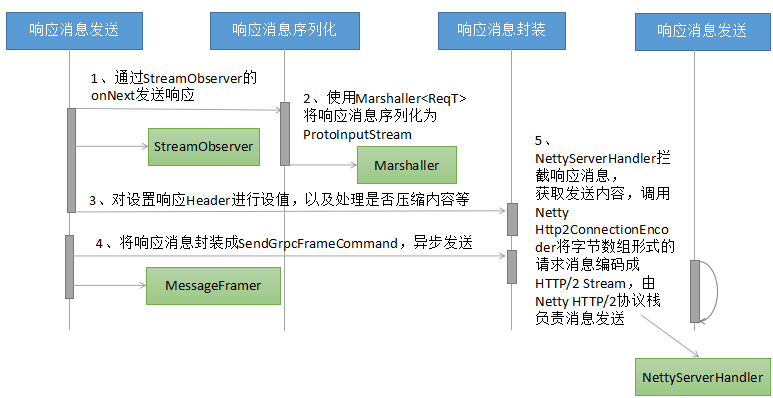
响应消息发送的主要步骤说明如下:
- 服务端的接口实现类中调用responseObserver.onNext(reply),触发响应消息的发送流程;
- 响应消息的序列化:使用Protocol Buffers的Marshaller工具类,对于生成的响应对象(继承自com.google.protobuf.GeneratedMessageV3)进行序列化,生成ProtoInputStream;
- 对HTTP响应Header进行处理,包括设置响应消息的content-length字段,根据是否压缩标识对响应消息进行gzip压缩等;
- 对响应消息进行二次封装,将序列化之后的响应消息封装成SendGrpcFrameCommand,通过异步的方式由Netty的NIO线程执行消息的发送;
- gRPC的NettyServerHandler拦截到write的请求消息之后,根据Command类型判断是业务消息发送,调用Netty的Http2ConnectionEncoder,由Netty的HTTP/2协议栈创建HTTP/2 Stream并最终发送给客户端。
3.3.2 工作原理与源码分析
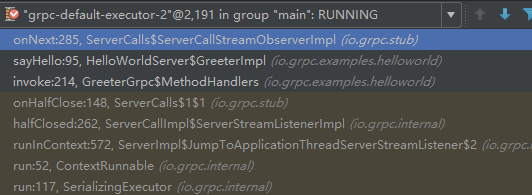
调用onNext方法,发送HTTP Header和响应(ServerCallStreamObserverImpl类):
public void onNext(RespT response) { if (cancelled) { throw Status.CANCELLED.asRuntimeException(); } if (!sentHeaders) { call.sendHeaders(new Metadata()); sentHeaders = true; } call.sendMessage(response); }在sendMessage中,调用Marshaller
public void sendMessage(RespT message) { checkState(sendHeadersCalled, "sendHeaders has not been called"); checkState(!closeCalled, "call is closed"); try { InputStream resp = method.streamResponse(message); stream.writeMessage(resp); stream.flush();...完成序列化之后,调用flush发送响应消息(AbstractServerStream类):
public final void deliverFrame(WritableBuffer frame, boolean endOfStream, boolean flush) { abstractServerStreamSink().writeFrame(frame, endOfStream ? false : flush); }将封装之后的SendGrpcFrameCommand加入到writeQueue中,异步发送(NettyServerStream类):
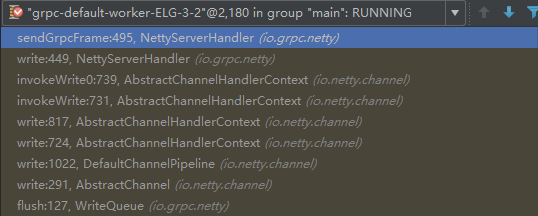
public void writeFrame(WritableBuffer frame, boolean flush) { if (frame == null) { writeQueue.scheduleFlush(); return; } ByteBuf bytebuf = ((NettyWritableBuffer) frame).bytebuf(); final int numBytes = bytebuf.readableBytes(); onSendingBytes(numBytes); writeQueue.enqueue( new SendGrpcFrameCommand(transportState(), bytebuf, false),...NettyServerHandler拦截到响应消息之后,根据Command进行判断,调用sendGrpcFrame,由Netty的Http2ConnectionEncoder负责将HTTP/2消息发送给客户端(NettyServerHandler):
private void sendGrpcFrame(ChannelHandlerContext ctx, SendGrpcFrameCommand cmd, ChannelPromise promise) throws Http2Exception { if (cmd.endStream()) { closeStreamWhenDone(promise, cmd.streamId()); } encoder().writeData(ctx, cmd.streamId(), cmd.content(), 0, cmd.endStream(), promise); }3.3.3 线程模型
响应消息的序列化、以及HTTP Header的初始化等操作由gRPC的SerializingExecutor线程池负责,示例如下:
HTTP/2消息的编码以及后续发送,由Netty的NIO线程池负责:
3.4 客户端响应消息反序列化
客户端接收到服务端响应之后,将HTTP/2 Body反序列化为原始的响应消息,然后回调到客户端监听器,驱动业务获取响应并继续执行。
3.4.1 数据流图
客户端接收响应的流程图如下所示:
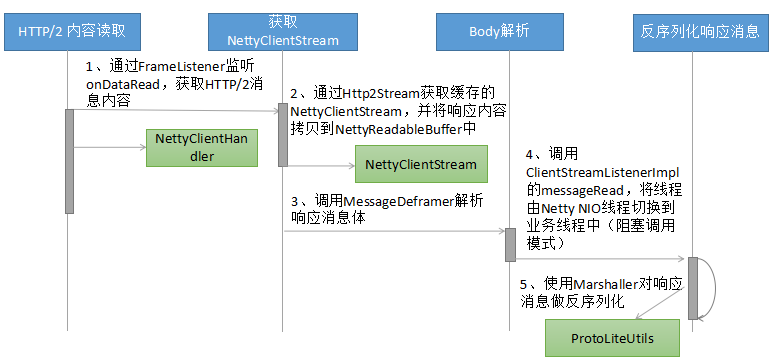
主要的处理流程分析如下:
- 与服务端接收请求类似,都是通过Netty HTTP/2协议栈的FrameListener监听并回调gRPC Handler(此处是NettyClientHandler),读取消息;
- 根据streamId,可以获取Http2Stream,通过Http2Stream的getProperty方法获取NettyClientStream;
- 调用MessageDeframer的deframe方法,对响应消息体进行解析。客户端和服务端实现机制不同(通过不同的Listener重载messageRead方法);
- 调用ClientStreamListenerImpl的messageRead进行线程切换,将反序列化操作切换到gRPC工作线程或者客户端业务线程中(同步阻塞调用);
- 调用Protocol Buffers的 Marshaller
对响应消息进行反序列化,还原成原始的message对象。
3.4.2 工作原理与源码分析
客户端接收到响应消息之后,根据streamId关联获取到NettyClientStream(NettyClientHandler类):、
private void onDataRead(int streamId, ByteBuf data, int padding, boolean endOfStream) { flowControlPing().onDataRead(data.readableBytes(), padding); NettyClientStream.TransportState stream = clientStream(requireHttp2Stream(streamId)); stream.transportDataReceived(data, endOfStream);...调用NettyClientStream的transportDataReceived,将响应消息拷贝到NettyReadableBuffer,进行后续处理(NettyClientStream类):
void transportDataReceived(ByteBuf frame, boolean endOfStream) { transportDataReceived(new NettyReadableBuffer(frame.retain()), endOfStream); }通过MessageDeframer的processBody处理响应消息体(MessageDeframer类):
private void processBody() { InputStream stream = compressedFlag ? getCompressedBody() : getUncompressedBody(); nextFrame = null; listener.messageRead(stream); state = State.HEADER; requiredLength = HEADER_LENGTH; }对于客户端,调用的是ClientStreamListenerImpl的messageRead方法,代码如下(ClientStreamListenerImpl类):
public void messageRead(final InputStream message) { class MessageRead extends ContextRunnable { MessageRead() { super(context); } @Override public final void runInContext() { try { if (closed) { return; } try { observer.onMessage(method.parseResponse(message));在此处,完成了Netty NIO线程到gRPC工作线程(被阻塞的业务线程)的切换,由切换之后的业务线程负责响应的反序列化,代码如下(ClientStreamListenerImpl类):
try { observer.onMessage(method.parseResponse(message)); } finally { message.close(); }调用MethodDescriptor的parseResponse:
public RespT parseResponse(InputStream input) { return responseMarshaller.parse(input); }源代码下载地址:
链接: https://github.com/geektime-geekbang/gRPC_LLF/tree/master